高层次芯片设计之High Level Synthesis
整理了高层次芯片设计课程High Level Synthesis部分的知识要点
FPGA Programming#
1.一些基本定义#
1.1 与C语言意义不同#
1.1.1函数将作为module
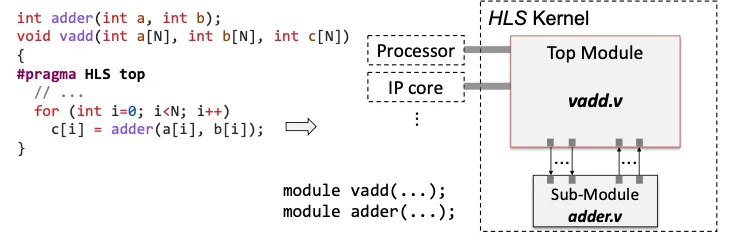
1.1.2 顶层函数的变量作为端口
需要附加声明 #pragma HLS interface m_axi port=A
m_axi 是 Memory AXI 接口的一种类型,表示模块与外部内存之间通过 AXI(Advanced Extensible Interface)总线进行数据交互。在 FPGA 中,AXI 接口是一种常见的协议,用于在不同硬件单元(如处理器、存储器等)之间传输数据。将模块的端口 A 配置为 Memory AXI 接口,表示它与外部内存通过 AXI 总线进行数据交换
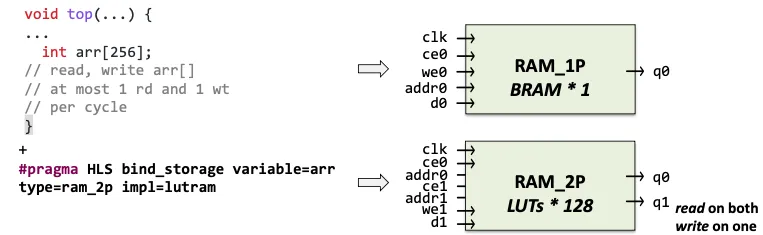
1.1.3 array作为memory
将数列绑定了存储资源,storage types: RAM_(1P/2P/…), ROM_(1P/…)
1.1.4 运算操作其实是产生硬件单元
1.1.5 控制流是一个状态机
1.2 数据类型#
• Standard types
• Signed/unsigned type: char short int long…
• Exact-width integer types
• Two’s complement (just like in C/C++)
• AP (Arbitrary Precision) data types
typedef ap_int<9> var1;
typedef ap_fixed<18, 6, AP_RND> my_type;
typedef ap_fixed<18, 6, AP_RND, AP_WRAP> my_type;
//该固定点数总共使用 18 位,6 位 来表示小数部分,四舍五入(rounding) 模式,包装模式(wrap-around)当一个数值超出表示范围时,它会“回绕”到最小值或最大值• Floating-point data types
typedef float data_t;• Composite data types
struct data_t {
unsigned int varA, varB;
unsigned short arr[16];
};
int top(data_t A[N]) {
#pragma HLS interface m_axi port=A
...
}• Vector
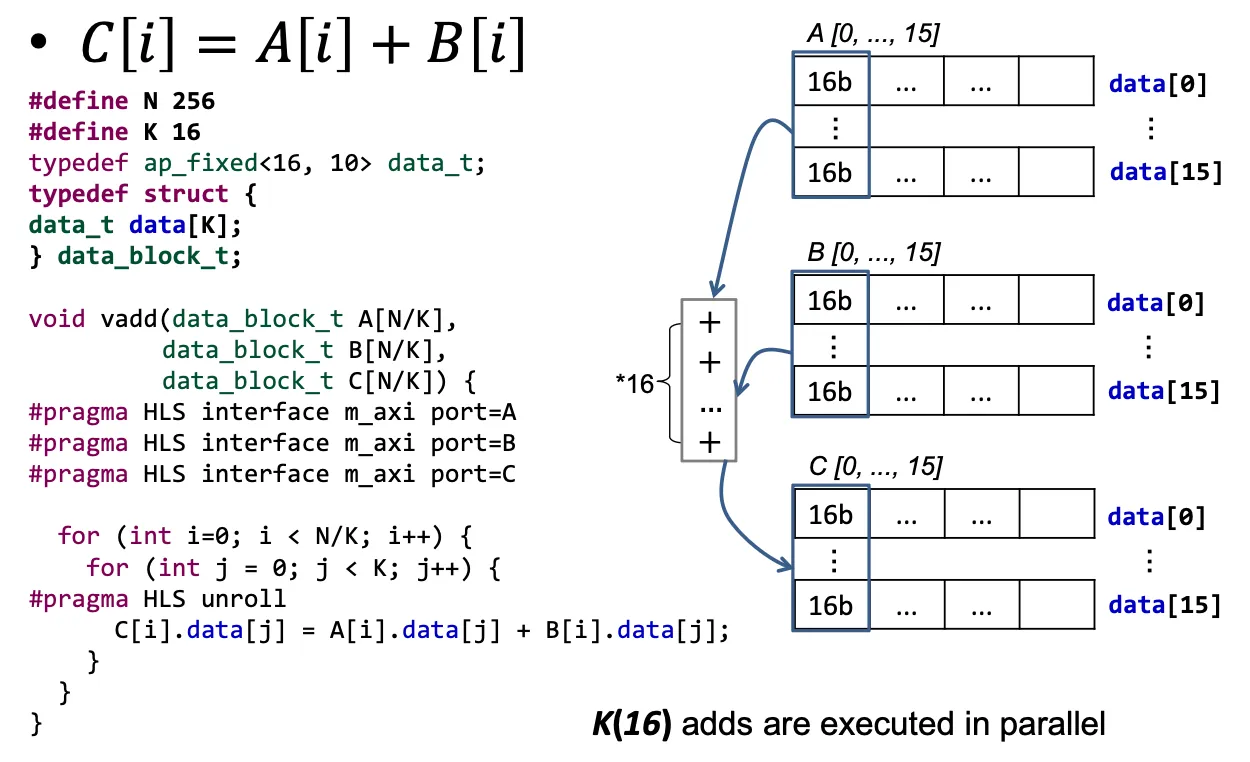
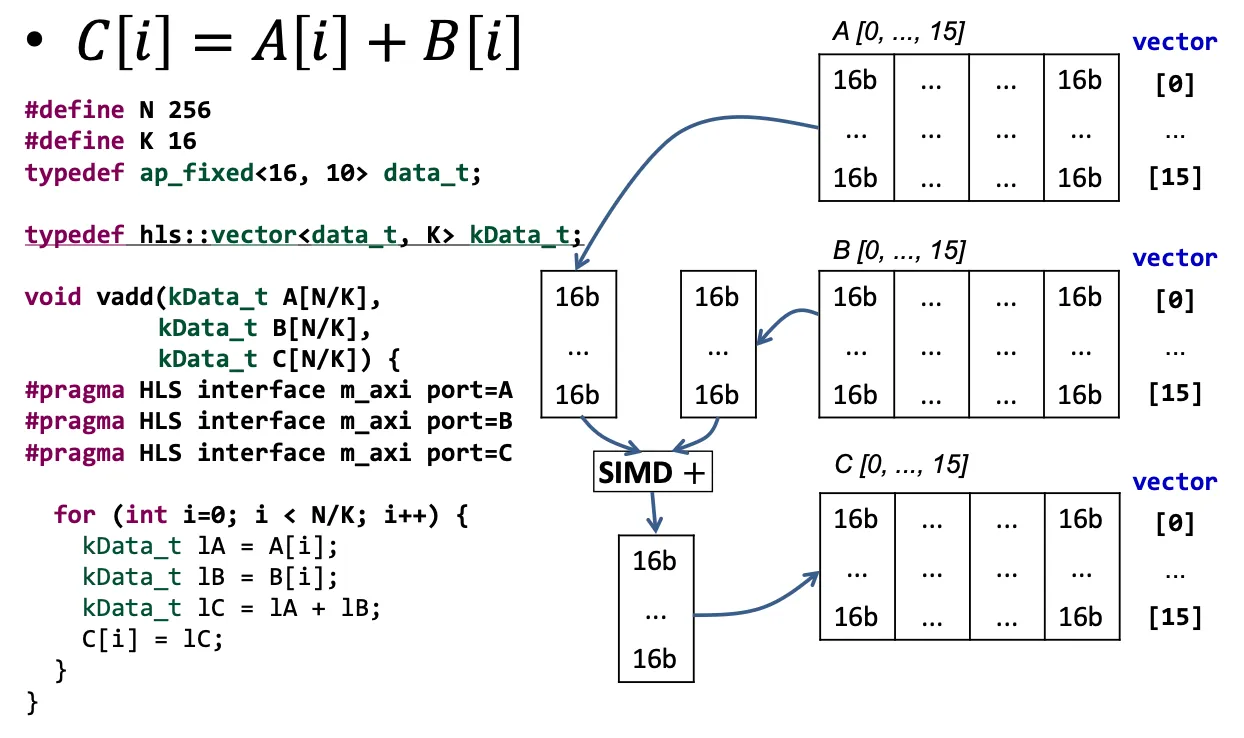
typedef ap_fixed<16, 10> data_t;1.3 structure & vector 并行计算区别#
写一个结构体,之后在循环中# p HLS unroll
或者直接采用vector进行计算
1.4 优化#
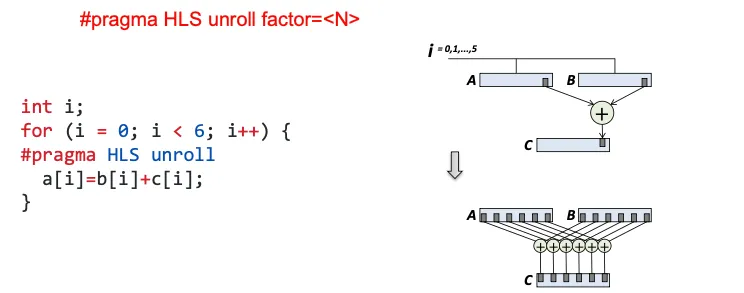
1.4.1 Loop unrolling: 循环展开
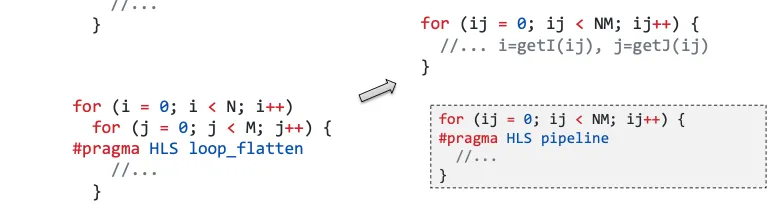
1.4.2 Loop Flattening 将嵌套的循环展平
1.4.2 Loop pipeline

1.4.4 基本代码优化 循环拆分
1.4.5 Array partitioning
#pragma HLS array_partition
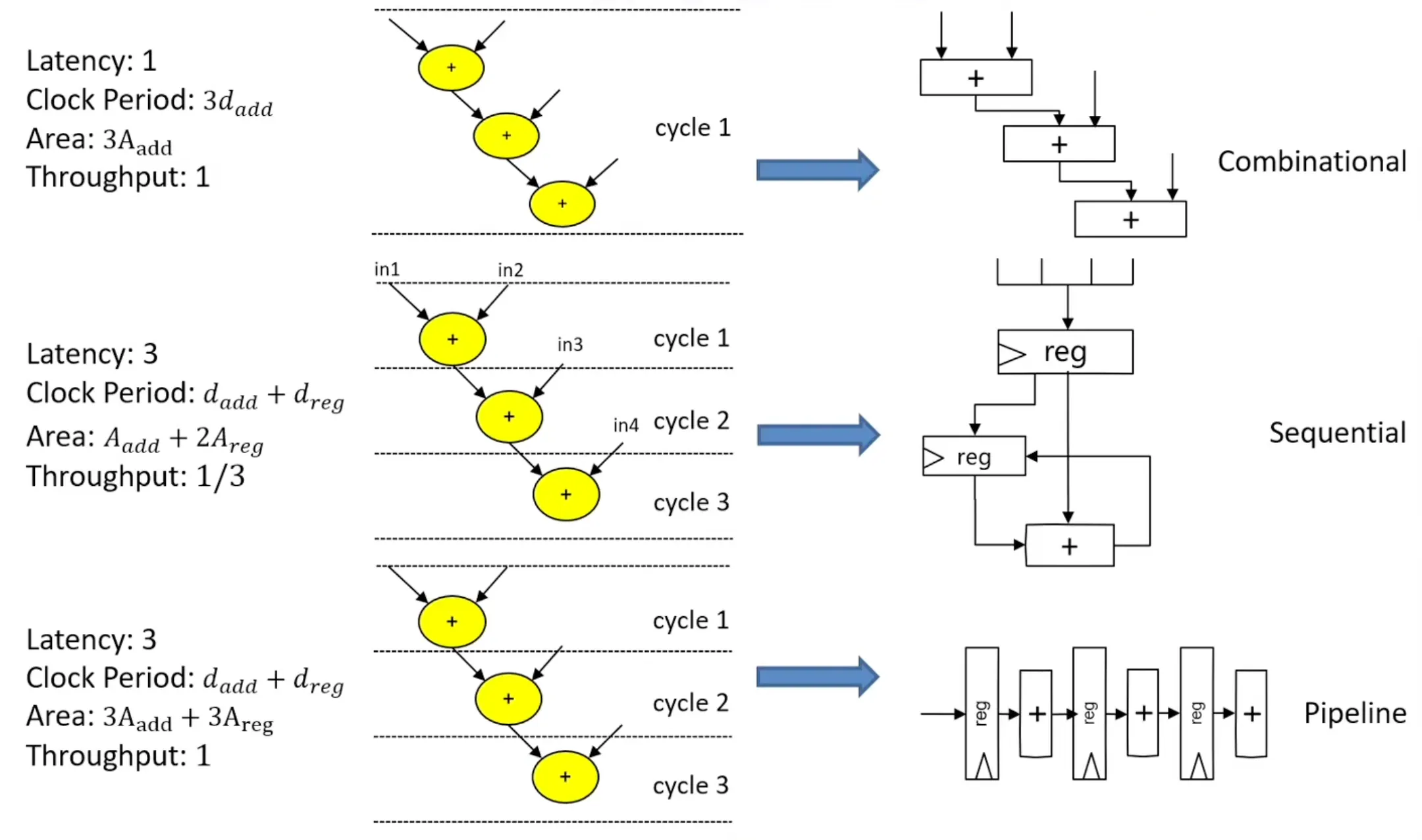
1.5 模块pipeline#
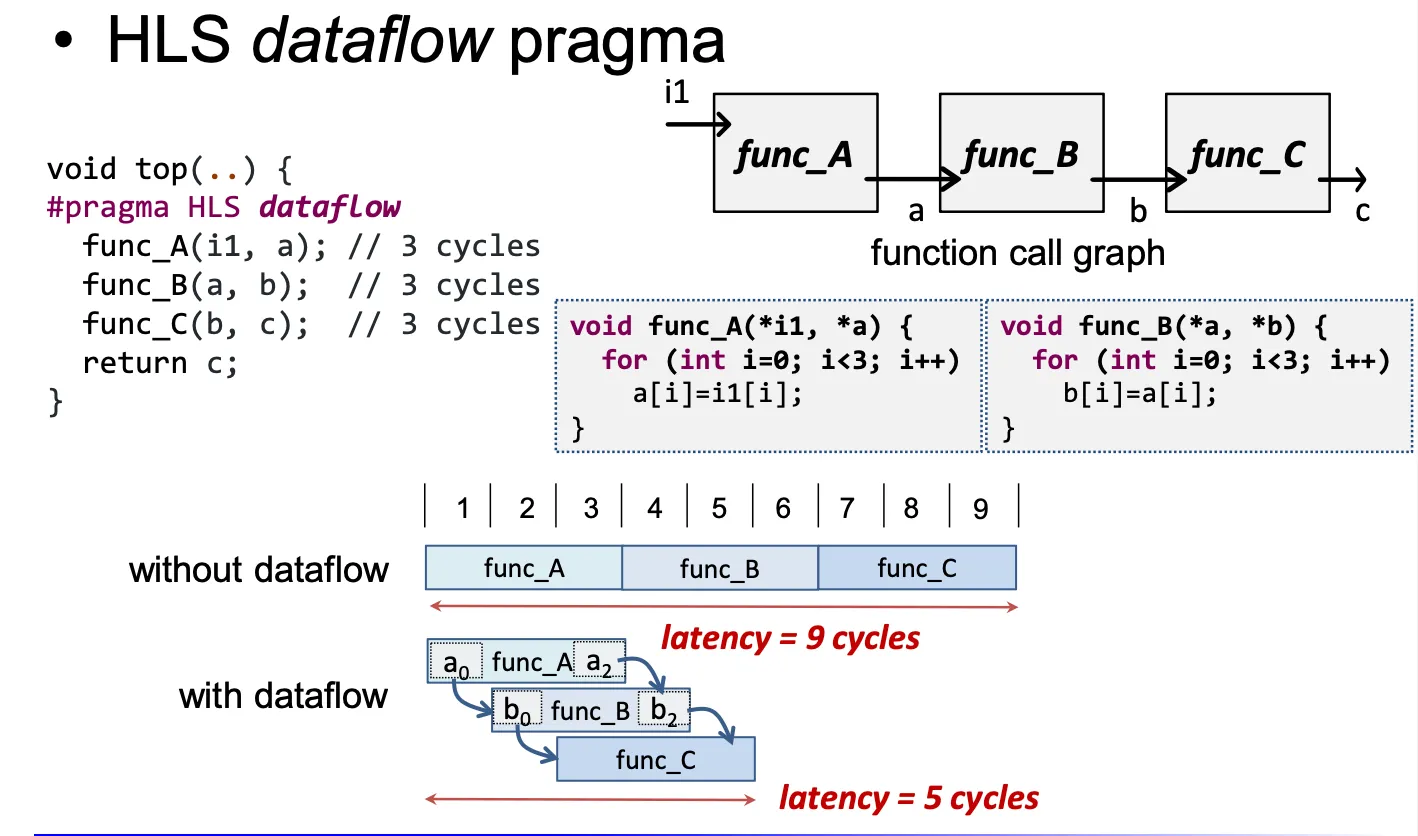
1.5.1 Task Pipelining 函数模块的pipeline
void func(.) {
#pragma HLS inline off
op_RD; // 1 cycle
op_Compute;// 1 cycle
op_WR; // 1 cycle
}对于一个循环运行的函数
#pragma HLS inline off //取消内连 否则简单函数他会自己展开
1.5.2 Task Parallelism

1.5.3 Datalfow
1.5.3.1
Producer-consumer Pattern 操作系统使用
Mutex:互斥锁 是一个bool信号
访问扩展共有资源channel 则先lock Mutex=1,
Semaphore:信号量
1.5.3.2 Handshake Protocol 没有操作系统的P-c 握手协议
Data Stream: FIFO
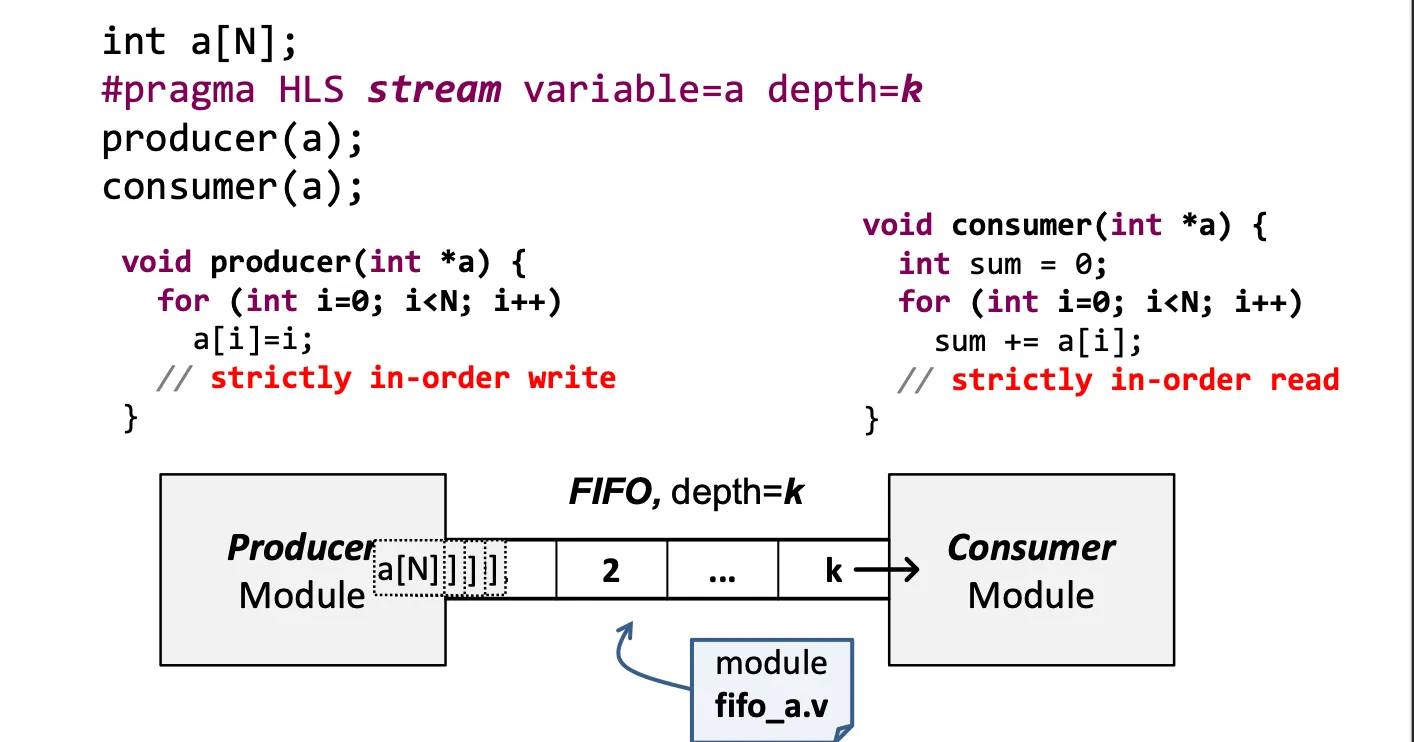
hls::stream<int> mystream;
int src = 42, dst;
mystream.write(src);
dst = mystream.read();1.5.3.3 Ping pong Buffer
1.5.3.4
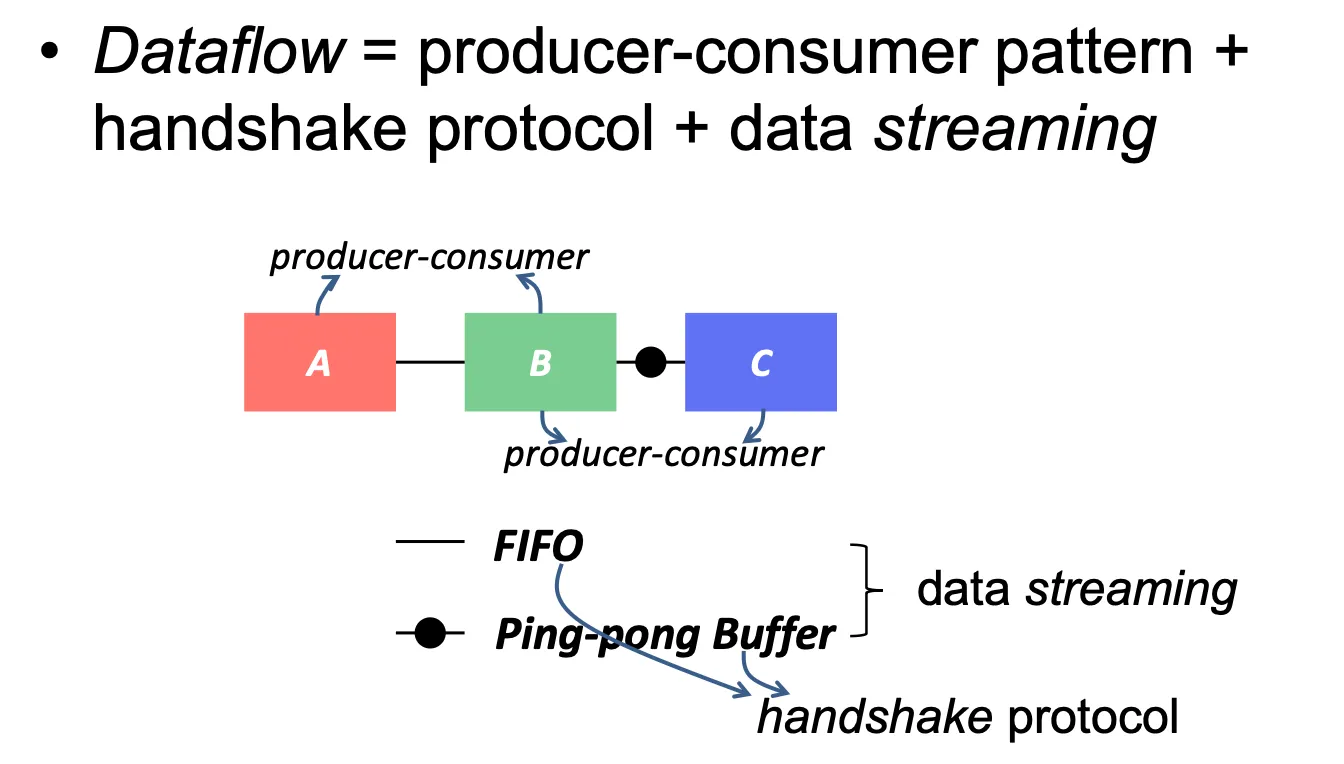
1.5 的总结

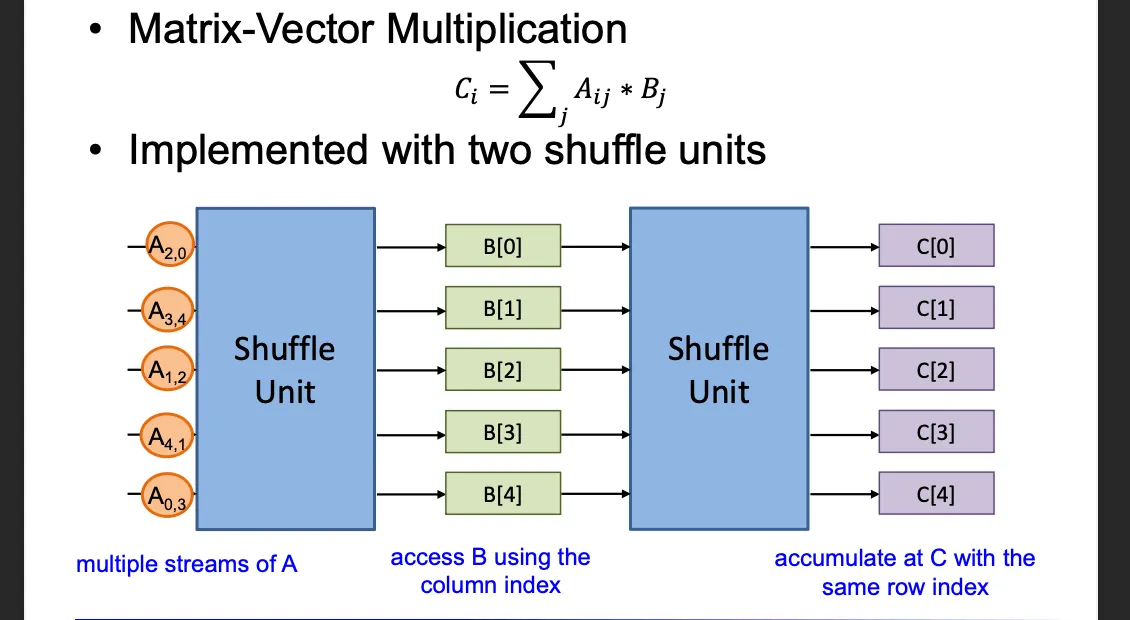
2. lab_shuffle unit#
High Level Synthesis#
Part1 高层次语言怎么变成verilog的#
P1-1 总览#
软件:控制流图
虚线:控制边 实线:数据传递边
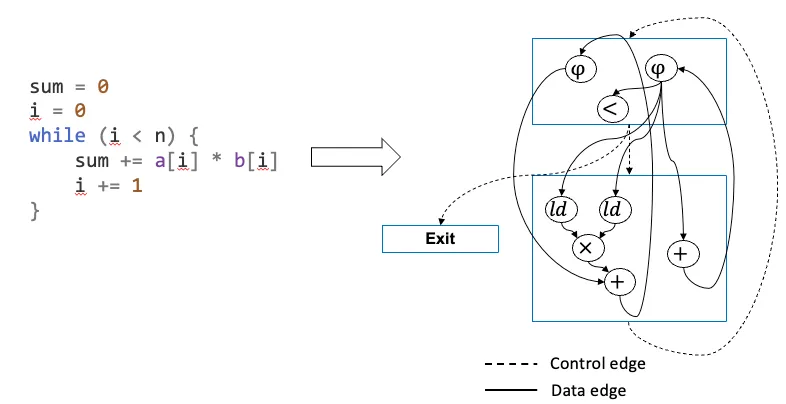

硬件:状态转移图 s0(初始状态)Vs(一些列状态)Es(有条件转移操作)
C语言 -编译→ 控制流图 -Allocation→ 计算资源 -Scheduling调度→ cycle图
1.Allocation
2.Scheduling
2.1.控制流图
Vbb 模块 Vop 操作 Ec 控制边 Ed数据依赖边
操作会带来delay latency
[1]代表依赖于上一个iteration的数据
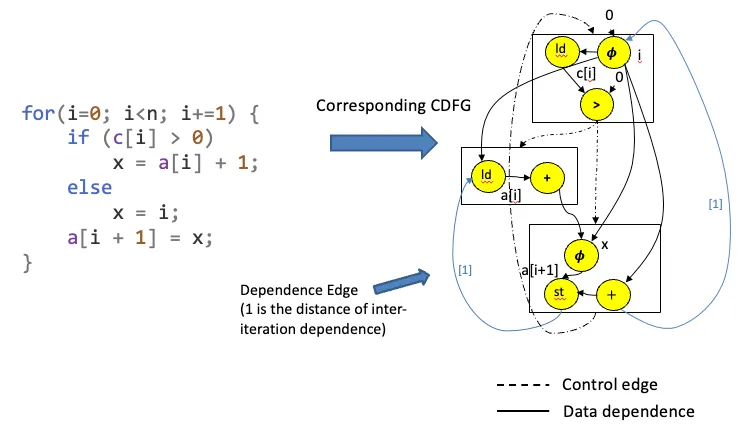
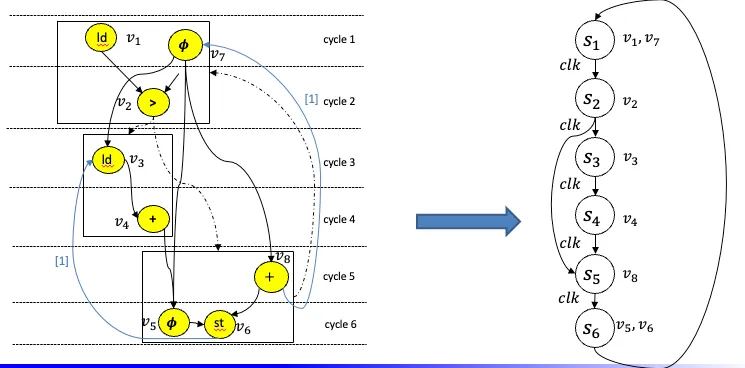
2.2.调度
3.Binding
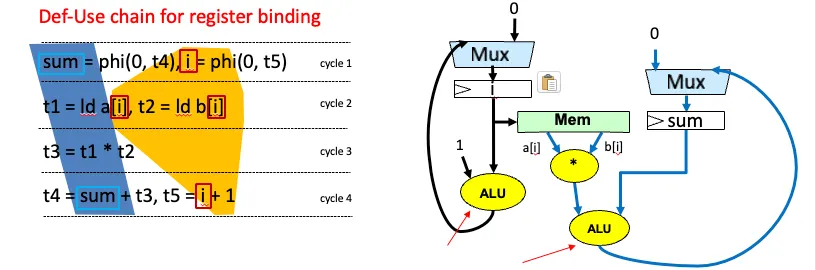
P1-2 调度的算法#
1.没有额外限制条件
1.1 ASAP算法
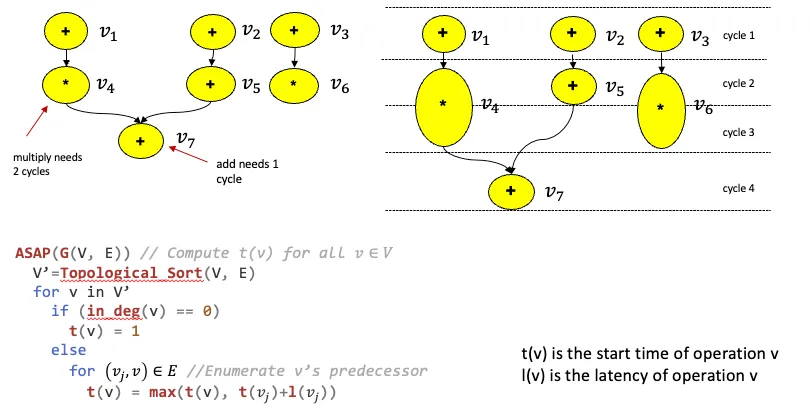
1.2 ALAP算法 限制延迟下的最慢操作
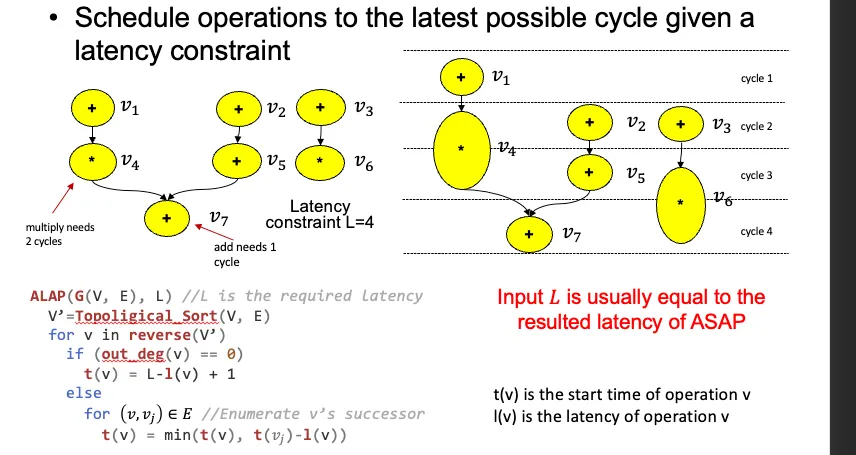
1.3 先ASAP获得L 在L限制下进行ALAP
2.资源限制条件
2.1 list scheduling算法(不一定最优)
基于ALAP算法排出优先级priority
每个cycle 列出ready_list 根据优先级先调度直到资源不够
3.延迟限制条件
3.1 Force-directed Scheduling FDS算法
时间窗口 Time Frame:每个操作ASAP和ALAP之间是可以存在的时间
调度概率:P=1/Time Frame
Distribution Graph: DG(c) 所有采用资源r的操作在c这个周期出现的概率和
目标:min_all.loc ( max_all.c DG(c) )让所有周期中最大的DGc最小
力Force: F最小最好:越大的DG(c)越希望被减小
3.2整数线性规划 ILP算法
二进制变量x_{it}; 操作opi在周期t被执行xit=1

依赖约束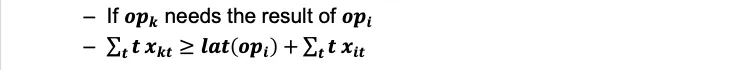
资源约束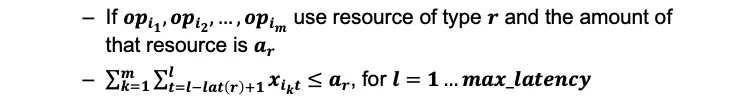
最终目标

4.其他算法 差分约束系统System of Difference Constraints
4.0 最短路径算法
Bellman-Ford算法
dijkstra算法
4.1 SDC 代表在第个周期调度
4.1.1 What is SDC
SDC是一种特殊的线性规划
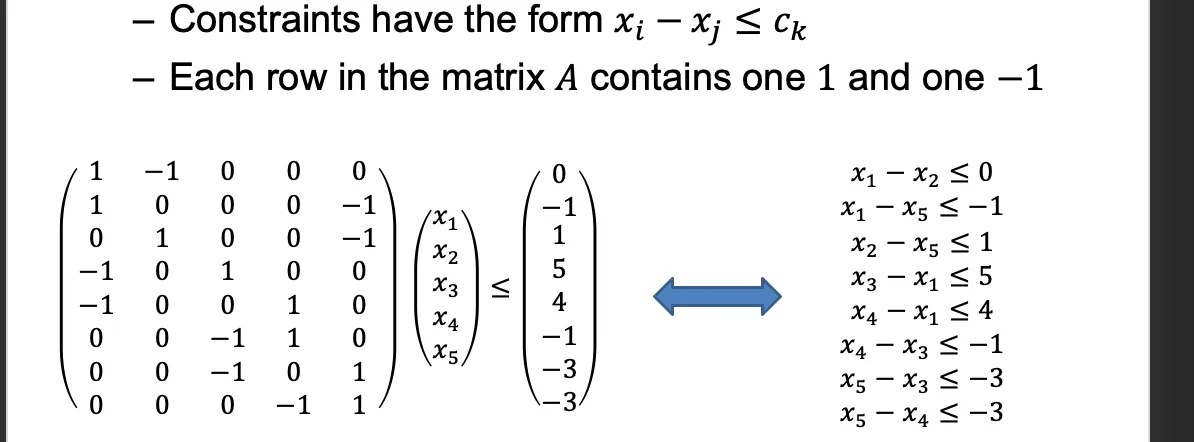
xi等价s到i的最短路解
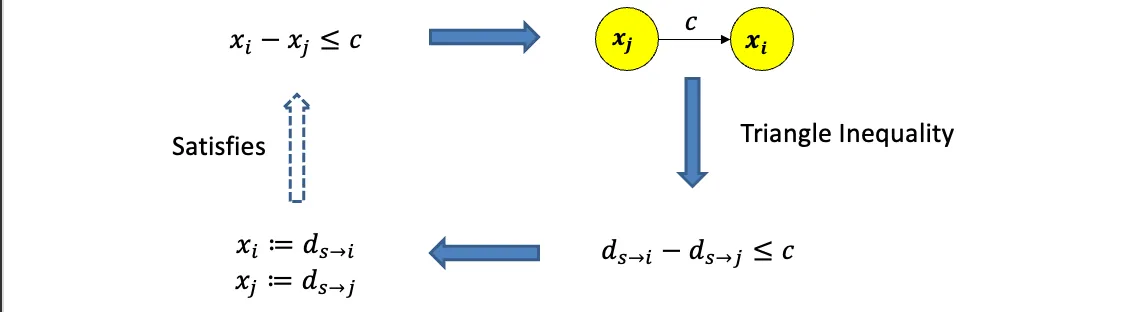
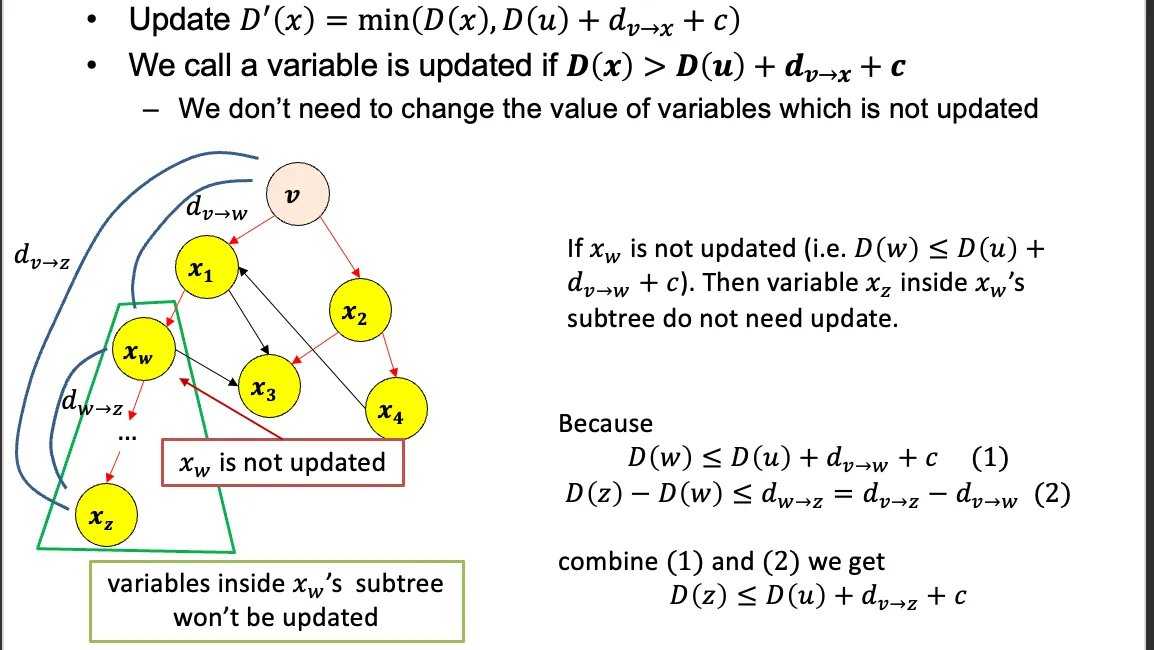
4.1.2附加额外条件后的解D(i)的更新
新增一个vu之间的约束关系,则只需要重新根据下面公式更新一下每个节点

剪枝(如果xw没被更新,那么最短路径树xw子节点可以不去更新)
4.1.3将边非负化的算法 Edmond-Karp算法
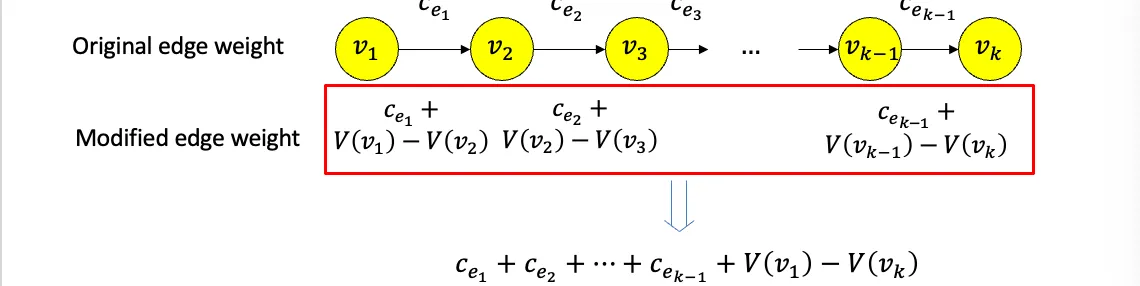
4.1.4 增加约束 总的流程
原始解 - 根据原始解进行E-K非负算法 - 从新增约束的被减数节点开始更新
4.2 SDC-based 怎么去列xi xj之间的不等式
依赖约束
相关时间延迟约束
operation chaining约束
延迟和小于时钟周期可以放到一个operation chain内 若大于则
资源约束
对资源先进行依赖拓扑排序,之后按照资源数与资源延迟进行不等式
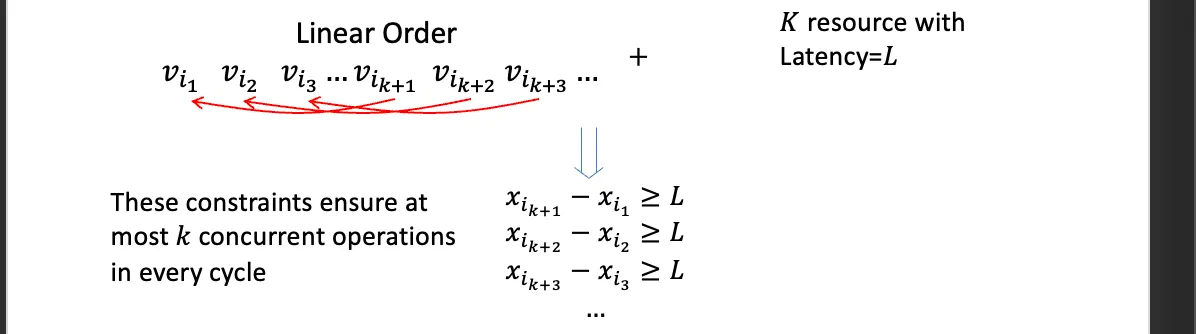
如果这个资源可以流水线(即输入第一个数之后II延迟后就可以输入第二个数)那么
4.3 Joint SDC
SDC不一定是最优解(只是在一定延迟要求和面积要求下的解),但希望找到一个延迟最小的最优解
4.3.1 Boolean Satisfiability Problem
对于一个布尔表达式有结果为T的解那么返回SAT 否则UNSAT
合取范式Conjunctive Normal Form

4.3.2 调度的布尔表达式
: opi使用资源k
: opi与opj共用资源
: opi严格早于opj
几个约束的Clause布尔表达式 (附:→推出的意思 左1则右边必须1)

上述的等价Clause布尔表达式

额外解可能导致负环
4.3.3
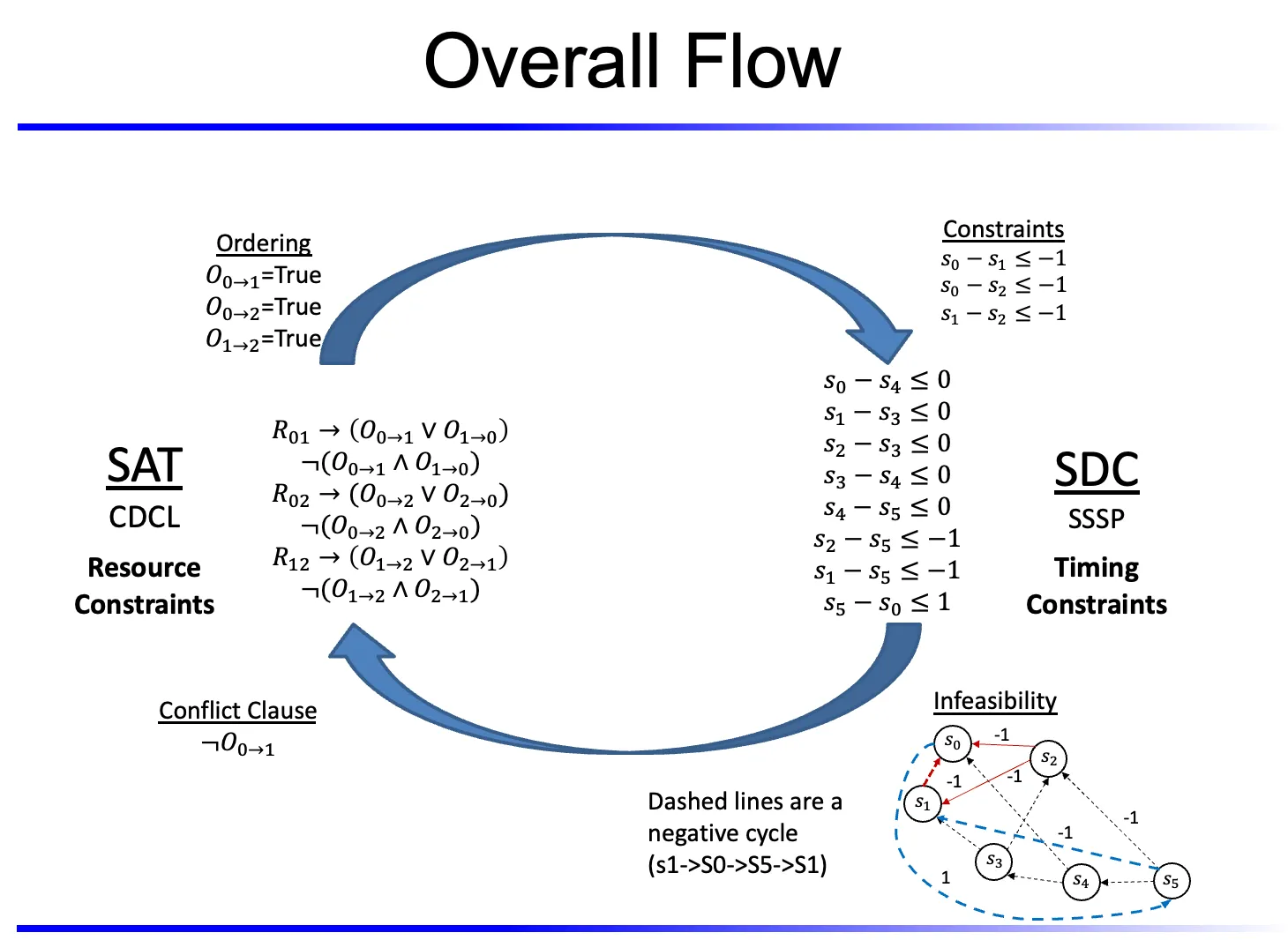
最外层有一个总latency二分搜索
对于每个latency
Part2 Loop Pipeline#
一个iteration(循环)中有多个operation(运算操作)
1.Dependence

2.SDC约束的式子
ti与tj代表同一个iteration中第几个周期运
2.1依赖约束
对于和两个操作,依赖必须在个iteration后执行,进行II流水
特别注意:如果op_i和op_j的运行时间和小于一个时钟周期长度,那么他们可以在同一个周期内完成(尽管他们之间有运算依赖)???
2.2时钟周期约束 如果op_i和op_j的运行时间合大于一个时钟周期长度
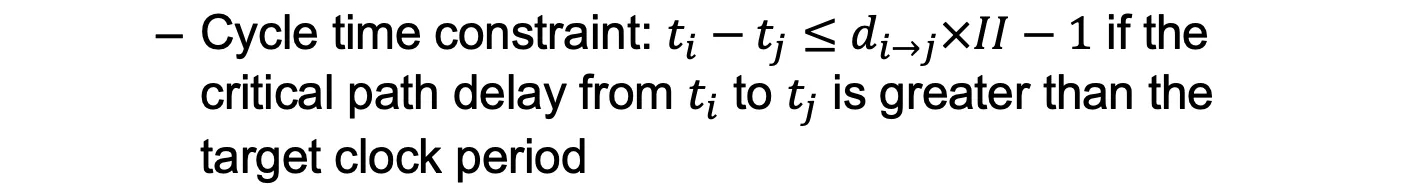
2.3 资源约束
3.总的算法
3.1找到Min II

ResMII就是每个资源 (需要该资源操作数/资源数) 的最大值
RecMII 先找环 这个环内所有op的latency之合/所有op的distance之合

3.2 找到II之间需要的寄存器数
只要有数据依赖 跨cycle的op 就需要寄存器 (考虑寄存器的位宽和个数)
生命周期 𝑙_𝑝≥𝑡_𝑞−𝑡_𝑝−𝐿𝑎𝑡(𝑜𝑝_𝑝 )+𝐼𝐼×𝑑_(𝑝→𝑞) 生命周期代表了需要多少个寄存器
Minimize w_i*l_i
3.3 合法化
不考虑资源约束 仅dependence求解SDC获得解refi 代入ti=refi看看是否资源合法
合法则加入ti=refi(refi-1<ti≤refi) 不合法则加入约束ti≥refi+1进入SDC条件 可以补一个t0去满足查分约束
找到Min II开始枚举II不断增大 → 仅dependence求解SDC获得解ci → 检验资源约束是否合法 → 不合法则加入约束直到求出解 或者 无解返回增大II
Part3 Allocation and Binding#
1.图的概念
1.1 Compatibility兼容:用同种资源,时间不重叠 ;Conflict冲突:不兼容
对于一个控制流图——兼容图(两个op节点兼容则用边连起来) 冲突图(控制节点取反)
1.2 Clique 团:一个图G的子图满足子图中任意两个点都有边相连(这是一个特殊的环)
团的节点数记为w(G)
1.3 独立集:一个图G的子图满足子图中任何两点都没有边相连
独立集的节点数记为(G)
1.4 clique partitioning分割成一系列团 团的数量越少越好
vertex coloring: 相邻点不同色 颜色越少越好 最少颜色数为𝜒(𝐺)
图G 的clique partitioning的结果 等价于 其补图 的vertex coloring的结果